AI in Rehabilitation Medicine: Opportunities and Challenges
Article information

Abstract
Artificial intelligence (AI) tools are increasingly able to learn from larger and more complex data, thus allowing clinicians and scientists to gain new insights from the information they collect about their patients every day. In rehabilitation medicine, AI can be used to find patterns in huge amounts of healthcare data. These patterns can then be leveraged at the individual level, to design personalized care strategies and interventions to optimize each patient’s outcomes. However, building effective AI tools requires many careful considerations about how we collect and handle data, how we train the models, and how we interpret results. In this perspective, we discuss some of the current opportunities and challenges for AI in rehabilitation. We first review recent trends in AI for the screening, diagnosis, treatment, and continuous monitoring of disease or injury, with a special focus on the different types of healthcare data used for these applications. We then examine potential barriers to designing and integrating AI into the clinical workflow, and we propose an end-to-end framework to address these barriers and guide the development of effective AI for rehabilitation. Finally, we present ideas for future work to pave the way for AI implementation in real-world rehabilitation practices.
INTRODUCTION
Artificial intelligence (AI) is poised to revolutionize the healthcare industry. By combining intelligent algorithms with massive volumes of training data, AI systems can solve problems and make logical inferences more quickly and reliably than humans, and they can also learn from larger and more complex datasets [1]. While early healthcare AI applications have focused on automating technical tasks (e.g., detecting arrhythmia from electrocardiograms [ECG], or segmenting and interpreting medical images), new advances are shifting AI into broader areas of screening, diagnosis, treatment, and prevention of disease and injury, as well as clinical decision support [2,3]. Within these emerging domains, AI offers many unique and exciting opportunities in rehabilitation.
The portfolio of rehabilitation therapies and interventions has expanded significantly over the last few decades, including new strategies for high-intensity training, assistive robotics, pharmacologics, and neurostimulation. However, many clinicians struggle to identify the most effective strategies for individual patients that will maximize their functional recovery and minimize their impairments [4]. Often, rehabilitation systems favor a one-size-fits-all approach, wherein patients receive similar therapy structures and dosages based on the best-known evidence and nationwide insurance reimbursement models. Another challenge is that patient information is often siloed in each care setting. That is, although a wealth of patient information is scattered throughout the healthcare system (e.g., regular check-ups with a primary care physician, or emergency room visits from previous trauma), there is limited accessibility and interoperability of information between different settings (Fig. 1A) [5,6]. As a result, clinicians may not have all the information they need to design the best treatments for a patient, which reduces the efficacy and efficiency of care.
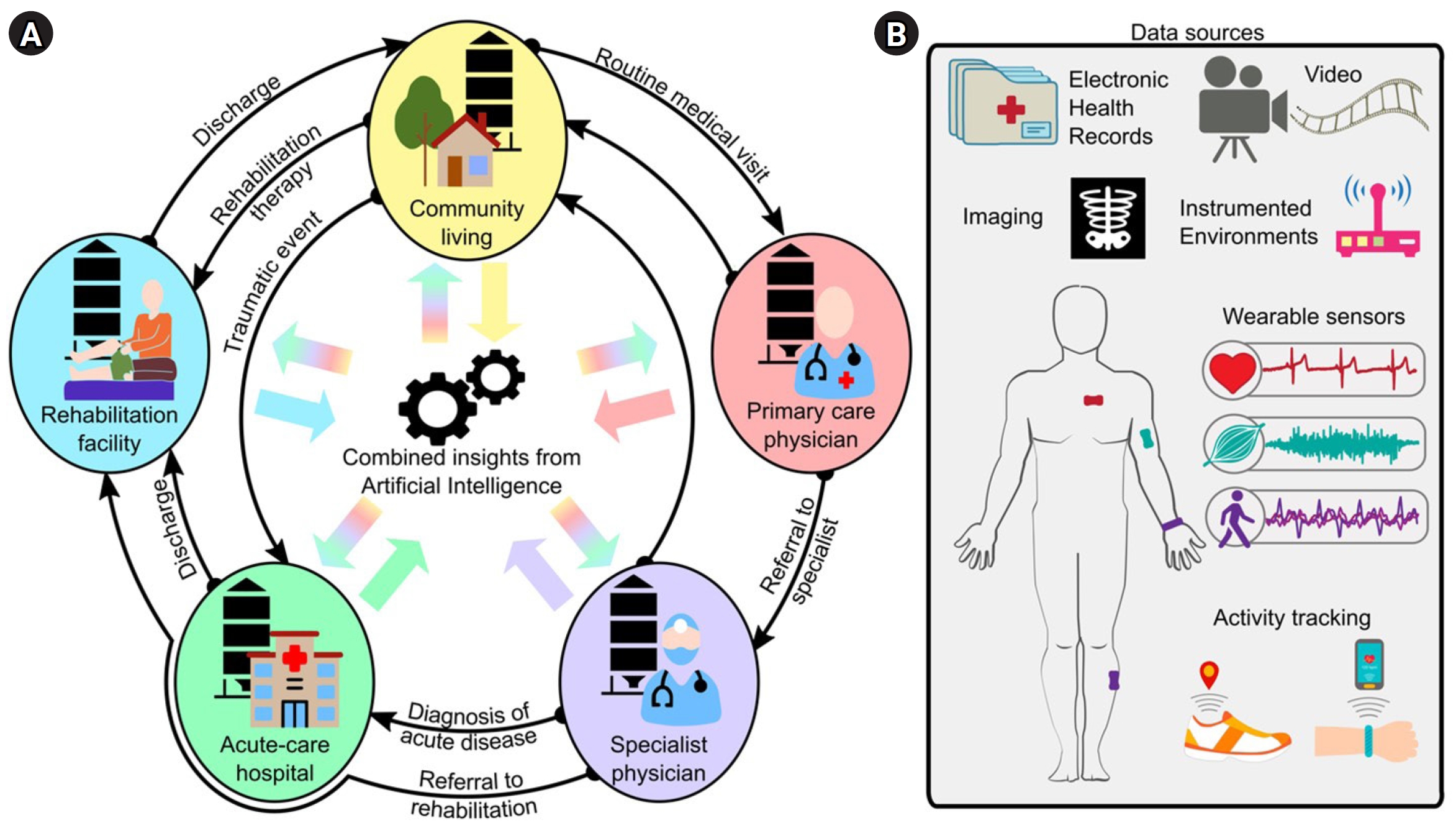
Data for rehabilitation medicine. (A) Traditionally, data is siloed in the different stages of medical care (e.g., community living, primary care physician, specialist physician, acute-care hospitals, rehabilitation facilities, etc.), with limited data mobility as patients transition between care settings. Artificial intelligence (AI) can integrate this information for a tailored and comprehensive evaluation of the health status of an individual. (B) Example data sources for AI applications in rehabilitation medicine.
With progressive shifts toward digitalized medicine and portable technology, there is more data available than ever before for us to understand the time course of disease and recovery for different patient cases. AI models—specifically, machine learning algorithms—can be trained to mine the existing data silos and combine complex data to identify patient- or population-specific biomarkers of disability, disease, and injury (Fig. 1). This approach has the potential to revolutionize how we assess patients, both in the clinic and out in the community, and empower us with actionable knowledge. For instance, AI tools could support the design of tailored rehabilitation programs precisely matched to specific impairments [5], timely referral decisions [7], and comprehensive care plans for clinicians and families. The result would directly address the surging demand for personalized and precision medicine in healthcare [2], enhancing patient engagement, cost-effectiveness, and the overall quality of care [8].
In this perspective, we examine the opportunities and challenges for AI in rehabilitation medicine. First, we explore the current research trends in this field, highlighting unique insights from different types of data. Second, we identify key barriers that are impeding the translation of AI into everyday clinical practice. Third, we propose an end-to-end framework for creating clinically meaningful AI models for rehabilitation applications. Lastly, we discuss potential directions for future work.
THE DATA LANDSCAPE: WHICH DATA ARE USED FOR AI IN REHABILITATION?
A person’s health can be described by an extensive amount of data (Fig. 1). In a medical care setting, health data may include diagnostic exams, functional test scores, medications, and laboratory analyses, complemented by demographic information, medical history, comorbidities, and additional clinical notes [9,10]. These data are usually recorded in an electronic health record (EHR) for each patient, which is continuously updated and reviewed by the clinical team. Additionally, advances in wearable sensor technology have enabled continuous, high-resolution monitoring of vitals and activity during the hospital stay and, notably, in people’s homes and community [11]. Instrumented environments and video recordings can also collect these data in a contactless, non-intrusive way. Each of these data sources and example applications for rehabilitation are discussed below.
Electronic health records
EHRs are a wellspring of information for AI, often serving as the de facto data source for models that are targeting automatic patient screening, early detection, and prognosis.
Screening and early detection are among the most popular and widespread applications of EHR-based AI in healthcare research. In contrast to traditional screening tools that require expensive, time-consuming procedures, AI models can learn subtle patterns and precursors of disease, and then automatically identify at-risk patients using longitudinal information stored in EHRs [12,13]. For instance, models trained on routine EHR data have detected autism spectrum disorder in infants as early as 30 days after birth (nearly one year earlier than standard autism screening tools) [14], and they have detected latent diseases in adults such as peripheral artery disease [15]. They have also identified individuals at high risk of falling [16], and predicted the development of pressure ulcers within the first 24 hours of admission to an intensive care unit [17]. In these examples, earlier detection and more accurate screening can help clinicians intervene with appropriate care or prevention strategies, thereby improving patient care quality in rehabilitation.
Additionally, EHR-driven AI can be used for early, data-driven prognosis, which would assist with short- and long-term care planning, patient goal setting, and identifying appropriate candidates for different treatments [18,19]. In acute stroke rehabilitation, prognostic models have recently shown promise IN PREDICTING future walking ability [20-22], functional independence [21,23], and balance [21] at an inpatient rehabilitation facility (IRF). These models have incorporated EHR data (e.g., demographic and clinical information) collected at IRF admission to predict a patient’s ability at IRF discharge. Beyond the inpatient setting, longitudinal predictions of postdischarge recovery can assist with outpatient therapy planning [24]. For instance, the TWIST algorithm was designed to predict the probability of independent walking recovery up to 26 weeks poststroke using early EHR data [25], while the PREP2 combines EHR and imaging data to predict upper limb function three months poststroke [26].
Imaging
AI can be trained to segment and interpret medical images, such as from X-ray radiography or magnetic resonance imaging, to detect disease-related anomalies such as tumor masses [27,28], cardiovascular abnormalities [29], retinal glaucoma [30], and reduced grey matter [31]. Markers extracted from medical imaging have supplemented EHR data in AI models to increase diagnostic accuracy, determine disease severity, or evaluate recovery potential [32].
Wearable sensors
Today’s wearable sensors can record a plethora of health-related information, spanning physiological, biomechanical, behavioral, and activity measures. Unlike EHR data, which are collected during brief patient-clinician interactions, wearable sensors can collect biometric data continuously and at much higher resolutions [33]. In the past, obtaining precise measurements of body kinematics, muscle activity, or vital signs required specialized environments, trained experts, and costly equipment. But ongoing technological advancements are bringing these and other measurements to wireless, portable, and cost-effective body-worn devices that can be deployed easily in any setting, including the community [11].
Wearable sensor data paired with AI are fostering new ways of measuring disease-specific indicators of function and impairment, complementing traditional clinical assessments [34]. For instance, inertial measurement units (IMUs), electromyography (EMG), or ECG sensors capture valuable data related to patient movement and neurological function. In acute stroke rehabilitation, we observed that sensor data improved the performance of a model predicting future walking ability, surpassing models using only EHR and other standard clinical information [35]. Similarly, sensor data during walking have been combined with clinical information to estimate dynamic balance ability in individuals with stroke, multiple sclerosis, and Parkinson’s disease [36]. In the upper limb, IMUs have shown promise in assessing motor deficits in stroke and traumatic brain injury during the Wolf Motor Function Test [37], or evaluating tremor and bradykinesia for individuals with Parkinson’s disease [38,39]. Novel sensors recording high-frequency vibrations can also quantify and monitor swallowing impairment for individuals with dysphagia [40]. These and other sensor-based AI tools can be used to monitor disease progression and therapy impact [41].
Consumer smartphones and smartwatches also incorporate various sensors, including IMUs to capture movement, GPS (Global Positioning System) modules to track geographic location, and optical sensors to estimate vitals such as heart rate and blood oxygenation. AI analysis of these signals can generate diverse measures of physical activity and step count [42], movement impairment [33], community mobility [43], heart rate and cardiovascular health [44], sleep [45], fall risk [46], and more. We recently applied AI to consumer wearables data to assess postoperative recovery in patients who underwent pediatric appendectomy, analyzing patterns in patient activity, heart rate, and sleep measures to detect early signs of complications [47]. Activity recognition algorithms from wearable devices can also indicate exercise adherence or changes in daily activities post-IRF discharge [48].
Instrumented environments
Instrumented environments are an emerging technique for patient monitoring. By strategically installing sensors in the patient’s surroundings, this approach is a markerless and contactless method of collecting clinically-meaningful data in the hospital or at home. For example, devices emitting low-power radio signals can estimate respiration and heart rate by analyzing the signals reflected off the body [49]. Combining these data with AI could enable continuous vitals monitoring or symptom evaluation for COVID-19 [50], Parkinson’s disease [51], and other conditions. Like wearable sensors, instrumented environments may offer significant economic advantages by reducing the need for regular clinic visits [52].
Videos
Another markerless data acquisition technique is human pose estimation, which uses AI to automatically detect body landmarks from videos and quantify movement, function, and impairment [53]. Pose estimation is becoming more commonplace in applications like gait analysis, since it reduces dependency on costly optoelectronic motion capture equipment. Video-based gait metrics have been computed in healthy populations [54], people with Parkinson’s disease [55] and stroke [56], as well as for general functional assessment [57].
More recently, AI has been applied to automatically score clinical assessments from video, such as the Movement Disorder Society Unified Parkinson’s Disease Rating Scale in individuals with Parkinson’s disease [58], or the General Movements Assessment in young infants [59]. In these examples, video-based AI offers a scalable solution to enhance the reliability and accessibility of valuable clinical assessments, which require specialized training and considerable practice for scoring.
BARRIERS TO AI IN CURRENT REHABILITATION PRACTICES
Despite the extensive research in AI and the burgeoning availability of healthcare-related data, integrating these models into real-world clinical practice remains a significant open challenge. We believe there are three key barriers that can fundamentally limit the translation of AI models in rehabilitation:
1. Lack of interoperability: As described above, AI can combine clinical and community data to make intelligent inferences about a patient’s current, past, or future health. However, the heterogeneous nature of data reporting across different sources can lead to biased, inaccurate, or inexecutable models [7]. To mitigate this, data reporting should be standardized to ensure the interoperability of data that can be curated for the models [60].
2. Lack of transparency: The black-box nature of AI can also limit its widespread adoption in rehabilitation [61]. Uncertainty about the computational processes or validity of AI, paired with inevitable model errors and performance fluctuation during initial deployment and ongoing tuning, can easily generate feelings of distrust for AI decision-support tools. To make models transparent, developers should provide clinicians with accountable and user-friendly guidelines to interpret the goodness of AI predictions and potential sources of error.
3. Lack of actionability: Insights from AI should also be actionable, enabling clinicians to identify or modify care strategies to improve patient outcomes [62]. Different techniques have emerged in recent years to explain the complex interactions across features used by the models [61,63]. Information from the most predictive or model-driving features could help clinicians design new treatment strategies for their patients. However, all models and their underlying features should be interpreted with caution since they do not always reveal causal effects.
Additional operational or performance barriers—including requirements for data storage and security, cost constraints, resource limitations, education and training challenges, regulatory and ethical complexities, and issues related to scalability and generalization—can also impede AI implementation. Overcoming these additional barriers at the site will require close collaboration between AI developers, healthcare providers, institutional regulators, and policymakers.
FRAMEWORK FOR AI DEVELOPMENT IN REHABILITATION
We offer an end-to-end framework to address the three key barriers above and guide AI development for rehabilitation. The framework identifies the high-level processes needed to bridge the gap between multidimensional data input and meaningful model output in the clinical or research setting. The framework also details the specific steps at which to incorporate the attributes of interoperability, transparency, and actionability to maximize the translational impact of AI in rehabilitation.
Defining the target output
When developing AI for any application, defining the model’s output and use case is essential. In rehabilitation, the model output may be automated scores from standard clinical processes (e.g., gait speed, balance score, heart arrhythmia count), novel measures of body function and impairment not typically available in a clinic (e.g., joint kinematics, gait symmetry, muscle activation), or a prediction of a patient’s outcomes (e.g., disease detection, prognosis, discharge location). The model may be intended for use in specific circumstances in the clinic or community, across or within patient groups, and/or during continuous, real-time monitoring or a snapshot in time.
Clinicians and researchers familiar with the target output can provide insights on appropriate data to capture the target output based on potential confounds of disease, medication, comorbidities, and so forth. These expert collaborations are critical for robust AI development in the highly specialized rehabilitation setting, increasing the chances of successful translation.
Translating healthcare data into the target output
After defining the target output, AI developers can follow a 7-step framework to obtain the output from available healthcare data (Fig. 2). Although the attributes of interoperability, transparency, and actionability should be considered throughout the framework, we will identify the particularly relevant attributes for each step.
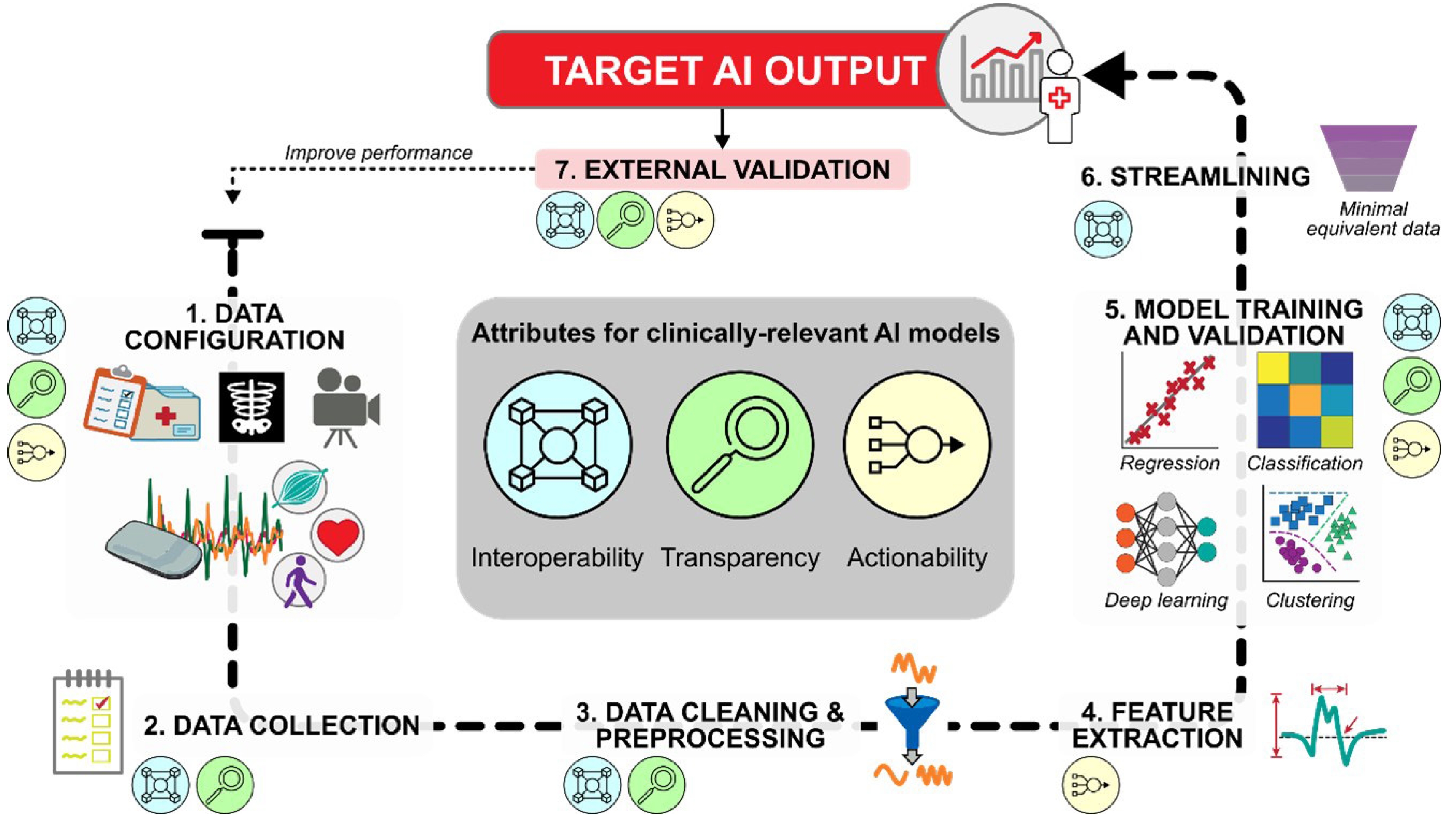
Framework for developing artificial intelligence (AI) models with clinically relevant attributes. Input data, such as EHR (electronic health record), imaging, sensor data, or video recordings (see Fig. 1B), are first selected and validated for their ability to capture the desired target output. Single/multimodal data streams are collected, processed, and passed to AI algorithms for inferential and/or predictive analytics. After establishing baseline model performance, streamlined datasets can be tested to determine the minimal data needed to achieve this performance, thereby supporting practical clinical implementation. The final model should be externally validated to determine its generalizability to an independent dataset. If performance is not satisfactory, the framework can be revisited in whole or in part.
Step 1. Data configuration
The first step is selecting and configuring the data source(s) for the AI model (e.g., see Fig. 1B). For example, developers may need to decide the specific variables to be collected from each source, the recording parameters and placement of sensors/cameras/instrumentation, and the recording duration and frequency. These and other configuration decisions will directly impact the nature and quality of recorded data, as well as the downstream interoperability and actionability of the AI model.
When using EHR data in an AI model, developers should include EHR variables with established or hypothesized relationships to the target AI output. For instance, age, comorbidities, and medication use have all been linked to gait speed prediction [64]. Including known predictors of the target output will likely account for more inter- and intrasubject variance, thereby maximizing model performance.
When using wearable sensor data, developers should carefully consider options for different sensing modalities, body location, adhesion methods, and sampling characteristics to capture the signal of interest while minimizing problematic noise. For example, detecting gait events from IMUs is typically improved by placing a body-worn sensor closer to the point of impact with the floor [65]. Using multiple sensors on different body locations can increase the accuracy of activity detection [66] or sleep stage monitoring [45], although it may also increase power consumption and reduce patient compliance. Preliminary studies considering multi-sensor systems should begin with more complex configurations to capture enough predictors and data resolution for the target output, then streamline as necessary (see Step 6. Streamlining).
When using video recordings, the choice of cameras can affect the AI model performance [52]. Conventional 2D RGB cameras are generally suitable for automatic annotation and pose estimation. Depth cameras may offer improved accuracy for certain applications, such as activity recognition, particularly when combined with other sources like wearable sensors [67] or thermal cameras [68]. Video recording configurations, such as frame rate or resolution, and environmental conditions, such as lighting or occlusions, should be carefully considered, as these decisions can impact data quality, storage, and processing time.
Before using technology-acquired data as inputs to an AI model, such as measurements from sensors or video, there should be established evidence that these measurements accurately represent the true values (e.g., of motion, vitals, activity, etc.). These measurements should be validated against the “gold standard” measurement technique to assess their accuracy, reliability, and agreement level [69-71]. Measurement validation should, as best as possible, include the expected environmental conditions and patients that are representative of the model’s expected use case [48,72,73]. Protocols for measurement validation should be reported in detail to increase the later AI model’s transparency to potential sources of error. This will help users understand whether the input data and model can be used, or whether they should be interpreted differently, outside of the validation conditions.
Step 2. Data collection
Data collection for AI training and testing should obtain high-quality data that are representative of the expected use case, such as during real-world clinical scenarios and from a diverse patient cohort.
Determining the appropriate sample sizes for training and testing data for robust AI is an ongoing challenge in this field. Generally, large amounts of data from diverse samples will create a more generalizable model, and multiple repetitions of the data collection protocol for each patient will account for intrasubject and intersubject variability.
Data annotations are critical to contextualize and select appropriate data during model training. Example annotations might include the activity type (e.g., walking, plantarflexion, sleep stage, etc.), clinical test scores, EHR items, use of assistive devices or orthotics, or required assistance levels for activity completion. Failure to collect a well-distribution set of annotated data leads to imbalanced datasets and/or algorithms with inherent biases, such as to race, gender, and age [74,75]. Understanding the interactions between algorithm performance and the contextualized data, as well as their ethical implications, should guide data collection practices to mitigate potential sources of bias. This will also allow other developers to reproduce the models and integrate new data, leading to larger, more diverse datasets and enhanced AI reliability and validity.
Step 3. Data cleaning & preprocessing
Data collected in controlled laboratory or research environments is often cleaner and easier to annotate than data collected in real-world settings like clinics, homes, and communities. Data sources like EHR, wearable sensors, and videos often contain data artifacts, such as transcription errors, discrepancies in patient documentation, missing values, poor recording conditions, and technology failures. To mitigate these issues, the dataset undergoes cleaning and initial processing, such as harmonization, handling missing data, resampling, filtering, and other transformations.
Data harmonization involves expressing data into a common architecture, thereby facilitating interoperability between data sources and rehabilitation sites. For EHR data, harmonization might include standardizing categorical information, such as patient demographics or medical conditions, in formats or categories used in different EHR datasets [76]. For other data sources, harmonization can include using uniform measurement scales or synchronizing temporal data, such as when recording multiple time-varying signals (e.g., from sensors, video, imaging, etc.) during a single clinical task.
Missing data poses a critical challenge for AI. Missing data might arise for numerous reasons, such as incomplete data entry, data loss from devices not being worn (or worn with a depleted battery), software glitches, or patient noncompliance. The most straightforward solution is to exclude samples with missing data from the dataset, but this drastically reduces the available data for model training. Alternatively, imputation approaches, such as statistical deduction, regression, or deep learning, can fill in missing data based on existing values in the dataset.
Data resampling is often required to align data from different sources and extrapolate missing samples. Depending on the scope of the analysis, the temporal granularity of the data can be either decreased (i.e., down-sampling, to simplify the data while keeping essential information) or increased (i.e., up-sampling, to capture finer details).
Filtering may also be required to isolate the bandwidth of interest of the signal from low-frequency noise (such as offsets and drifts), high-frequency noise (such as magnetic coupling), and interferences from other signals.
Depending on the data source, additional transformations may be necessary to improve data quality. For instance, sensors deployed to a patient in the community may not be worn in the exact orientation or placement as they were intended in the laboratory. Therefore, sensor calibration or baseline recordings can be used to “correct” the sensor signals with respect to a reference condition. Reporting transformations and other processing steps is important for transparency, allowing developers to generate replicable models based on the handling of the training data.
Data warping is an important concern during the cleaning and processing step. Although a primary goal is removing noise and enhancing the true target signal, an overly aggressive approach can obscure the authentic signal. This may reduce measurement resolution (e.g., aliasing), or prove impracticable with real-world datasets, ultimately compromising the performance and generalizability of an AI model.
Step 4. Feature extraction
Features are a set of values derived from processed data containing information related to the target output. This is a pivotal step to drive the actionability of the model, since these features can later be interpreted and acted upon.
Feature extraction varies in complexity, from extracting EHR fields to computing statistical moments from time-series signals (such as mean, standard, deviation, skewness, kurtosis from sensor or video data). Signal characteristics, including spatial, temporal, and frequency aspects, can also be engineered for clinical relevance. For example, wavelet transformations can estimate step length and stance time from IMU data [77,78] or fast Fourier transforms identify frequency bandwidths during muscle contraction in EMG signals [79]. EHR and annotation data offer additional contextual features [80], such as medications or assistive device use. For categorical or ordinal features, operations like one-hot encoding or ordinal encoding should be applied to prevent model bias [81].
Often, many extractable features are redundant (i.e., highly correlated) or irrelevant to the model. A feature set with high dimensionality increases the risk of overfitting the training data [82]. Feature selection techniques, such as dimensionality reduction or regularization, should be considered to reduce the feature set to those more strongly associated with the target AI output. This is often done in conjunction with Step 5. Model training and validation. Ultimately, the complexity of feature extraction and engineering is strictly linked to the modeling technique, since not all models require predefined features before training (e.g., deep learning).
Step 5. Model training and validation
Processed data and/or their features find utility in descriptive, predictive, or prescriptive models. Descriptive models elucidate underlying data measures not readily available in clinic settings. In contrast, predictive and prescriptive models infer current or future patient outcomes and offer clinical decision support, respectively, within the clinical context.
Algorithm selection depends on the intended use case of the AI tool, and each algorithm’s architecture and assumptions will affect data utilization (i.e., inductive bias [83]) and performance. For example, clustering algorithms group similar patients by measuring distance from decision boundaries [84]. Regression algorithms are used to estimate a function between input features and continuous outputs like time to hospital discharge or clinical score [85]. Classification algorithms identify discrete quantities, such as activities [48,72], or impairment and disease categories [38,40,86,87]. Deep learning models, including neural networks, directly learn patterns from data via reinforcement techniques [88]. Leading AI models can handle complex tasks, such as labeling unannotated data [89], generating new data [90], or interpreting unstructured text [91]. While the training process varies among different approaches, some common elements impact AI interoperability, transparency, and actionability.
Selecting appropriate validation techniques is crucial for reliable and robust AI development. Cross-validation (CV) is a process to optimize hyperparameters, scale data, select features, and evaluate model performance. In CV, a model is trained on one set of input data and evaluated on separate (“held out”) testing or validation datasets. Various methods are available to separate the training, testing, and validation datasets during AI development, including a ratio-based train-test-validation split, leave-one-out, k-fold, or Monte Carlo sampling [60]. For models intended to generalize to new patients, CV should be subject-wise, meaning that the training, testing, and validation datasets contain data from different patients, with no leakage between them [92]. For personalized models predicting outcomes for a single patient, these datasets might contain information from the same patient but recorded at different times. Improper CV can produce overly optimistic or even completely invalid models [92].
Postdevelopment, model evaluation should extend beyond traditional performance metrics like accuracy, F-scores, absolute error, or regression coefficients. Systematic analyses should examine performance variations when training or testing across different data or patient subgroups [60], as well as the consistency and importance of the features selected across iterations. These sensitivity analyses aid in understanding model stability, considering clinical use cases, and evaluating potential biases and overfitting.
Step 6. Streamlining
Comprehensive data and complex transformations may be needed to achieve the highest AI performance; however, practical considerations such as computational cost, processing time, data recording duration, data storage limits, and user burden can limit the real-world usability of AI models. In these cases, streamlining is an important step to determine the minimal equivalent data that are necessary to attain sufficient performance (Fig. 3). Example methods of streamlining are to reduce the number of data sources, reduce the data sampling frequency, or reduce the complexity of features used for the model. The goal of streamlining is to simplify the model to enhance its interoperability for scalable, real-world deployment.

Model streamlining. (A) Hypothetical illustration of the minimal equivalent data needed for a model. When paired with appropriate AI (artificial intelligence) practices, increasing the data resolution (e.g., adding data sources, increasing measurement frequency, increasing data complexity) can decrease model error (black curve) at the expense of greater computational burden (purple line). The minimal equivalent dataset (grey star) reduces the data resolution without substantial increases in error, thereby streamlining the model for more practical real-world deployment. (B) Example of a streamlining process for wearable sensor data. Descriptions on the right include data input during model training and testing, and the stepwise methods of streamlining in bold. Min. Eqv., minimal equivalent.
Step 7. External validation of the target output
A sufficiently regularized model should generalize well to unseen data. External validation determines the reproducibility of the AI’s performance when applied to an entirely new dataset, such as a different cohort, location, or later time point [93]. Successful external validation increases confidence in the model’s performance and enhances its credibility for practical use in the desired context. At this stage, user feedback can also help developers understand the model’s deployment feasibility in new clinical settings, as well as identify the frequency and consequences of potential errors.
CHALLENGES FOR FUTURE WORK
By combining large quantities of multimodal data, AI tools offer an exciting possibility to transform rehabilitation medicine from a one-fits-all paradigm to personalized, precision treatments for individual patients. However, small and potentially biased datasets, as well as difficult-to-interpret models, may impede AI adoption at scale. Here, we offer some considerations for future work to address these ongoing challenges.
Large datasets are not always feasible
The quantity and quality of model training data are fundamental considerations when creating scalable, accurate AI tools for rehabilitation. Ideally, these training data would be recorded from a massive, fully representative patient cohort to capture the complete range of disease and recovery conditions that can arise for the model’s target population. However, the practical challenges with collecting such datasets and the lack of data standardization mean that large, interoperable datasets are scarce in rehabilitation. Although data from large, multisite clinical trials and open-source repositories are beginning to address this gap, AI itself offers possible solutions to lengthy and costly data collection protocols.
Transfer learning is one such technique to harness knowledge from a previous AI model for a new application. Transfer learning involves adapting a model initially trained on one task or dataset to a different but related task or dataset. Importantly, this technique can drastically reduce the amount of data and computational resources needed for model training or retraining. For instance, transfer learning has been applied to classify lower-limb movements from EMG data using a previous model that predicted joint angle [94].
Annotating datasets with precise labels is time-intensive. Self-supervised learning (SSL) addresses this issue by automatically generating annotations from unlabeled data. SSL is valuable for unstructured, large datasets where defining annotations is challenging or impractical. SSL uses contrastive learning to compare similar and dissimilar samples, identifying features for sample description and classification [89]. Recent studies show SSL models perform on par with manually annotated data, especially with multimodal data [89], and they can be generalized across external factors [95]. However, SSL-generated labels may not always be accurate, requiring continuous external supervision and comparison to exemplary annotations.
AI can also generate synthetic data to build larger, more diverse, and more representative datasets for algorithm training. Synthetic data mitigates the challenges of collecting sensitive patient information or handling imbalanced and potentially biased datasets [96]. Synthetic data can also be utilized as external datasets to further test and validate AI tools before clinical deployment [97]. However, evaluating synthetic data quality is difficult. Some state-of-the-art algorithms such as generative adversarial networks employ a generator module to produce synthetic data and a discriminator to compare it against real-world data [90], facilitating authenticity controls by developers.
AI insights are not always interpretable
To create interpretable AI tools, data in the AI workflow should be both intuitive and relevant to the intended audience (Fig. 4). Intuitive data are easily interpreted within a clinical context and offer actionable insights, while relevant data transparently align with the question of interest. These characteristics are not mutually exclusive and can be considered on separate scales—ranging from intuitive to unintuitive, and from relevant to irrelevant [98]. Intuitive and relevant data development often accompanies Step 4. Feature extraction in the proposed framework.
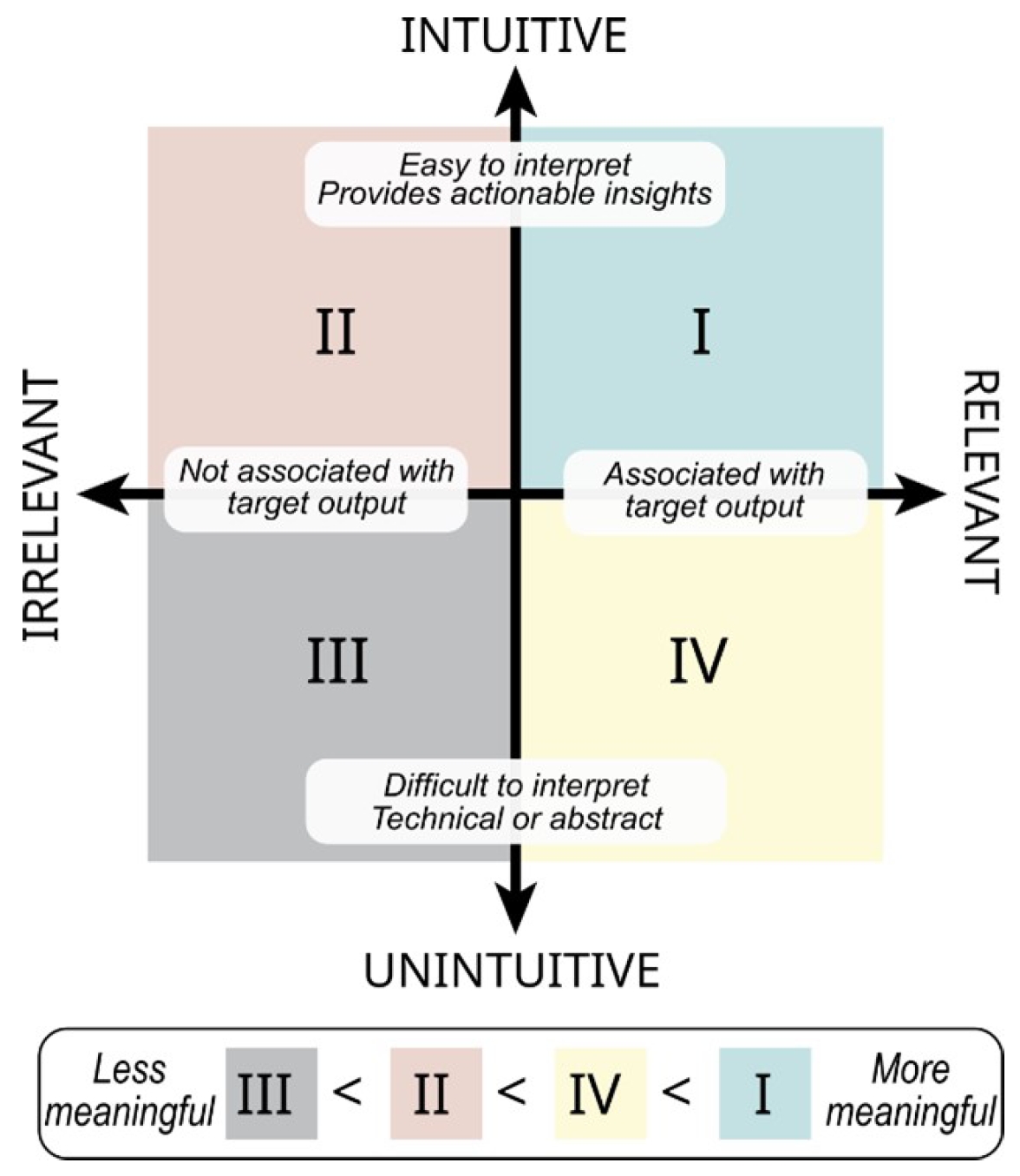
Data characterization for interpretable artificial intelligence (AI). The most meaningful data for interpretable AI models are both intuitive and relevant in clinical care (quadrant I, green). Data can be highly relevant to model performance but less intuitive, thus rendering it less actionable to a clinician during treatment (quadrant IV, yellow). Other data are highly intuitive and understandable to a treating clinician but less relevant, providing little-to-no value to the model (quadrant II, red). Data that are unintuitive and irrelevant should not be included in a model (quadrant III, grey).
Highly relevant but unintuitive data may be less actionable for clinicians during treatment (quadrant IV, yellow). For example, if a model indicates that the “second moment of the sample entropy” from an accelerometer during walking predicts the risk of knee injury, this may not give a clear, actionable insight for clinicians on reducing injury risks. Conversely, highly intuitive but irrelevant data may not provide the necessary information for the target AI output, rendering it even less meaningful (quadrant II, red). For example, precise measurements of skin hydration would not be useful to predict risk factors of cardiovascular disease, if there is no link between these two factors.
Complex data interpretation and novel treatment design can be supported by generative AI with large language models (LLMs) [99], similar to ChatGPT. LLMs trained on extensive EHR data show promise to reduce the administrative workload on clinicians, allowing them to generate automated reports or query specific patient information [91]. However, the safe and effective use of LLMs depends heavily on the quality of training data. Currently, these systems can still mislead users with outputs that are factually inaccurate and inconsistent with the input text [100]. Insights from experienced clinicians are vital to review and interpret AI output [101]. Developers and users should continuously assess AI models for factuality, comprehension, reasoning (i.e., by asking the model to show its reasoning process), possible harm, and bias [102].
Continued AI development after deployment
Evolving AI technologies, enhanced data infrastructure, and pervasive monitoring systems will gradually transform rehabilitation medicine, and more generally, healthcare. What are the challenges for researchers working in the field once AI tools are deployed?
Patients have multiple morbidities and a broad range of impairments that can complicate model predictions, especially for models trained under the assumption of a single and well-defined disease. As discussed, training models for every patient scenario is impractical, leading to inevitable errors. Until rigorous validation and trivial error rates are achieved, AI tools are best considered clinical support tools rather than autonomous agents, with clinicians playing the ultimate role in decision-making [103]. Consequently, we envision that there will be an increasing demand for AI implementation and usability studies in the near future. These studies may examine different user dashboards to convey AI output to clinicians, or the impact of AI tools on actual clinical practice and patient outcomes. There will also need to be additional regulations, such as the European AI Act, to define standards for a transparent, safe, secure, non-discriminatory AI-tools use before widespread adoption.
AI models should regularly integrate new training data to improve their representation and performance. Integrating new data can also reduce the likelihood of data drift, which occurs when new data introduced to an AI model differs from the data used for initial training. Data drift can arise from gradual or sudden changes in data acquisition methods, clinical treatments, disease patterns, or patient characteristics [104]. Therefore, it is crucial to monitor model performance and make adjustments even after AI deployment.
CONCLUSION
Rehabilitation medicine can benefit from recent advances in new data sources and modeling techniques to transition towards customized, precise, and predictive approaches. AI can help extract meaningful clinical insights from a wealth of healthcare data, but many challenges related to the development and interpretation of these tools can limit their success in real-world settings.
We proposed a general framework to build interoperable, transparent, and actionable AI tools for rehabilitation. In this framework, training data are configured and acquired in a manner that captures the use case of the intended AI tool, with a systematic approach to validation and interpretation for the patient group(s) of interest. Decisions should be made in consultation with expert clinicians who understand the pathophysiology of the impairment or condition being studied, and who can advise on potential confounds during real-world clinical or community scenarios. AI tools that consider these factors have great potential for automatically computing measures of activity and performance, illuminating novel biomarkers of injury and disease, and predicting patient outcomes using multidimensional factors related to health.
Notes
CONFLICTS OF INTEREST
No potential conflict of interest relevant to this article was reported.
FUNDING INFORMATION
This work was supported by the National Institute on Disability, Independent Living, and Rehabilitation Research (90REGE0010).
AUTHOR CONTRIBUTION
Conceptualization: all authors. Funding acquisition: Jayaraman A. Visualization: Lanotte F, O’Brien MK. Writing – original draft: Lanotte F, O’Brien MK. Writing – review and editing: all authors. Approval of the final manuscript: all authors.